Programmable Transformers
We propose to hardcode the parameters of a Transformer network in a new human-interpretable notation.
We propose to hardcode the parameters of a Transformer network in a new human-interpretable notation.
Deep learning is very effective at creating networks that can perform complex tasks, but we do not generally have much idea how those tasks are performed by these networks. We here propose some new notation that makes it far more possible to hardcode neural networks that can perform the same sorts of tasks as their learned counterparts. This has several benefits:
Our goal in this article is to successfully hardcode the weights
of a Transformer
Our first bit of notation is for sparse vectors whose nonzero
entries are small numbers. We first pick an ordered set of
natural language words (e.g., English words), one per dimension
of our vector space. We will call these
words semes.
When writing code, we omit the $$\langle\langle\, \rangle\rangle$$:
The next bit of notation is for sparse matrices whose nonzero
entries are small numbers. We represent the $$i,j$$ entry of a
matrix being $$x\ne 0$$ by $$\{\{ x \, seme_i \rightarrow
seme_j\}\}$$. If our three semes are again "pig",
"peregrine", and "wombat", then we have
When writing code, we omit the $$\{\{ \}\}$$ and use $$>$$ in
place of $$\rightarrow$$:
It is generally accepted that deep neural networks are
uninterpretable. We show in this article that they can be made
quite interpretable by using better notation, with no or very
little change to the architecture. Unfortunately, building a
network that is able to perform a nontrivial task is quite
complex and requires either a lot of preliminaries or intimate
familiarity with the architectures in question; we will
gradually build up to such networks. To whet the reader's
appetite, we show here a simple (vanilla) RNN designed to do
sentiment analysis, based on the VADER
algorithm.
The following figure can be edited interactively. We have provided a bare minimum set of word embeddings (below called "lexicon"), so adding additional examples will probably require adding additional items to the lexicon.
The process of hardcoding a network provides valuable insight into what kinds of computation are performable at all with the various components of a particular architecture, as well as what kinds of computation are natural (and thus likely easy to learn) and which kinds are unnatural (and thus at least potentially more difficult to learn). For an example, consider the first layer of a Transformer decoder. This layer takes in an embedding of the previously emitted word and performs various manipulations on it. However, there is a residual connection, so that the manipulations simply add things to the embedding of the previous word. This makes it somewhat difficult to erase the previous word's embedding, which is necessary to avoid simply repeating the previous word ad infinitum. This is relatively easy to address with a self-attention layer, but it suggests that a Transformer network would likely be well-served by adding a pointwise dense layer (without a residual connection) between the embedding of the previous word and the first decoder layer. It also suggests an explanation for the repetitiveness of Transformer networks in early training: the network has not yet learned to erase the embedding of the previous word sufficiently well. Hopefully further explanation will yield many more such insights and interventions.
3.3Hardcoding neural networks for natural language processing
allows us to encode linguistic knowledge in a format that is
usable for linguistic competence (e.g., grammaticality
judgments, entailment judgments, translation, dialogue), thus
allowing us to rigorously test the sufficiency of a linguistic
theory for explaining a particular phenomenon. Such work is not
in any sense new in linguistics (see
e.g.
There are several ways to combine hardcoded components with learned components to achieve some of the advantages of both. We list several ideas in this vein:
In this section, we lay out the workings of a Transformer piece-by-piece, indicating how each can be programmed. In the next section, we will actually build a network that classifies sentences as grammatical or not.
4.1As the next step, we will consider a pointwise dense layer, which requires one matrix parameter (the weights) and one vector parameter (the biases). Pointwise dense layers are used to compute the inputs to dot-product attention, as well as in the feed-forward layers of the Transformer.
As a basic example, consider semes $$apple,banana,cherry,durian$$. Consider the dense layer with weights $$\{\{apple\rightarrow apple, -apple\rightarrow banana, -apple \rightarrow cherry, -banana \rightarrow apple,$$ $$banana \rightarrow banana, -banana \rightarrow cherry, -cherry \rightarrow apple, -cherry \rightarrow banana,$$ $$cherry \rightarrow cherry\}\}$$ and bias $$\langle\langle -durian\rangle\rangle$$. The following figure allows you to change both the parameters of the dense layer and the vectors that get run through it.
Our ultimate goal is to write down all the weights for a Transformer model that can perform a natural language task. We next discuss word embeddings. For simplicity, we omit the intermediate step of associating each word to an integer identifier, and simply map each word directly to a vector.
| Word | Embedding |
|---|---|
| I | $$\langle\langle +nom +sg +first +pro\rangle\rangle$$ |
| you | $$\langle\langle +nom +sg +second +pro\rangle\rangle$$ |
| he | $$\langle\langle +masc +nom +sg +third +pro\rangle\rangle$$ |
| she | $$\langle\langle +fem +nom +sg +third +pro\rangle\rangle$$ |
| it | $$\langle\langle +neut +sg +third +pro +expletive\rangle\rangle$$ |
| me | $$\langle\langle +acc +sg +first +pro\rangle\rangle$$ |
| you | $$\langle\langle +sg +pl +second +pro\rangle\rangle$$ |
| him | $$\langle\langle +masc +acc +sg +third +pro\rangle\rangle$$ |
| her | $$\langle\langle +fem +acc +sg +third +pro\rangle\rangle$$ |
| we | $$\langle\langle +nom +pl +first +pro\rangle\rangle$$ |
| they | $$\langle\langle +nom +pl +third +pro\rangle\rangle$$ |
| us | $$\langle\langle +acc +pl +first +pro\rangle\rangle$$ |
| them | $$\langle\langle +acc +pl +third +pro\rangle\rangle$$ |
| my | $$\langle\langle +gen +sg +first +pro\rangle\rangle$$ |
| our | $$\langle\langle +gen +pl +first +pro\rangle\rangle$$ |
| his | $$\langle\langle +masc +gen +sg +third +pro\rangle\rangle$$ |
| her | $$\langle\langle +fem +gen +acc +sg +third +pro\rangle\rangle$$ |
| its | $$\langle\langle +neut +gen +sg +third +pro\rangle\rangle$$ |
| their | $$\langle\langle +gen +pl +third +pro\rangle\rangle$$ |
| meet | $$\langle \langle+meet +verb +plain +agentlack +patientlack\rangle\rangle$$ |
| meets | $$\langle \langle +meet +verb +thirdsg +agentlack +patientlack \rangle\rangle $$ |
| met | $$\langle\langle +meet +verb +preterite +agentlack +patientlack\rangle\rangle$$ |
| pig | $$\langle\langle +pig +noun +sg\rangle\rangle$$ |
| pigs | $$\langle\langle +pig +noun +pl\rangle\rangle$$ |
There are several things to note in these word embeddings.
Firstly, a "content" word like "meet" or "pig" will generally
have either itself or some other form of itself as one of its
components
We describe the intended use of some the semes we use here:
| Type | Seme | Meaning | Example |
|---|---|---|---|
| Weirdness | $$weird$$ | Some linguistic expectation has been violated | I are |
| Number | $$sg$$ | Singular | dog |
| $$pl$$ | Plural | dogs | |
| Case | $$nom$$ | Nominative case | I/they/she/he |
| $$acc$$ | Accusative case | me/them/her/him | |
| $$gen$$ | Genitive case | my/their/her/his | |
| Person | $$first$$ | first person | I/me/mine/myself |
| $$second$$ | second person | you/your/yourself | |
| $$third$$ | third person | she/her/he/him/his/they/them/their | |
| Role | $$agent$$ | One who performs an action | She threw the ball |
| $$experiencer$$ | One who experiences some perception | He saw a dog | |
| $$percept$$ | Something that is perceived | He saw a dog | |
| Role Requirement | $$agentlack$$ | Used for verbs that require an agent | She threw the ball |
| $$experiencerlack$$ | Used for verbs that require an experiencer | He saw a dog | |
| $$perceptposs$$ | Used for verbs that can take but do not require a percept | He saw a dog / He saw |
Next we consider the feed-forward layers of Transformer. These are typically two dense layers with a ReLU nonlinearity between them. The intermediate dimension (referred to as the "filter size") is usually larger (typically by a factor of four) than the hidden size of the network.
One of the primary uses we have found for the Transformer
feed-forward layer is to allow us to reason about logical
conjunctions ($$a$$ AND $$b$$) and logical disjunctions ($$a$$ OR
$$b$$). A single dense layer does not have the representational
capacity to represent either of these notions in a satisfactory
manner. In a Transformer feed-forward layer, we can represent
$$a$$ AND $$b$$ as $$f_{a\, \mathrm{AND}\, b}(v) =
\mathrm{ReLU}(v\cdot \{\{a\rightarrow x, b\rightarrow x\}\} -
\langle\langle x \rangle\rangle)$$. Here we can read the value of
$$a$$ AND $$b$$ out from the coefficient of $$x$$ in
$$f(v)$$. Similarly we can represent $$a$$ OR $$b$$ as $$f_{a\,
\mathrm{OR}\, b}(v) =v\cdot \{\{ +a\rightarrow x, +b\rightarrow
x\}\} - f_{a\, \mathrm{AND}\, b}(v)$$ $$=v \cdot \{\{
+a\rightarrow x, +b\rightarrow x\}\} -\mathrm{ReLU}(v\cdot
\{\{a\rightarrow x, b\rightarrow x\}\} - \langle\langle x
\rangle\rangle)$$. We now present editable code. The provided
code maps $$apple$$ OR $$banana$$ to $$yum$$ and $$cherry$$ AND
$$durian$$ to $$yuck$$.
Finally, we come to the most iconic layer of the Transformer, the attention layer. This layer is the only layer in which the representations of different words interact.
For now, we deal only with a single attention head for simplicity. Later, we will consider multi-head attention. For the time being, we are not using positional embeddings, which greatly restricts the ability of the network to associate nouns with the correct modifiers (and you will see such errors in the output of the next figure). We will address this shortcoming later, once we have some slightly better notation.
Here we explain the positional encoding of Transformer. The positional encoding is made of of sines and cosines of different frequencies. It turns out that this makes the embedding a concatenation of a bunch of clock hands. This interpretation is shown in the figure below. There are 7 clocks in the figure below, one for each of the frequencies we are considering. Click on any of the words (or their corresponding number) to see the positional embedding corresponding to that word. Each word receives the positional embedding that is the 14-dimensional concatenation of the seven clock hands described as vectors.
Why is this useful? It allows us to write weights that interact
with the positional embeddings (which is necessary to make
position-dependent inferences) without losing interpretability.
We do this as follows: first, we note that we can identify
rotation matrices that move each of the clock-hands forward by
the same amount that moving forward one word will move them. We
express this like so:
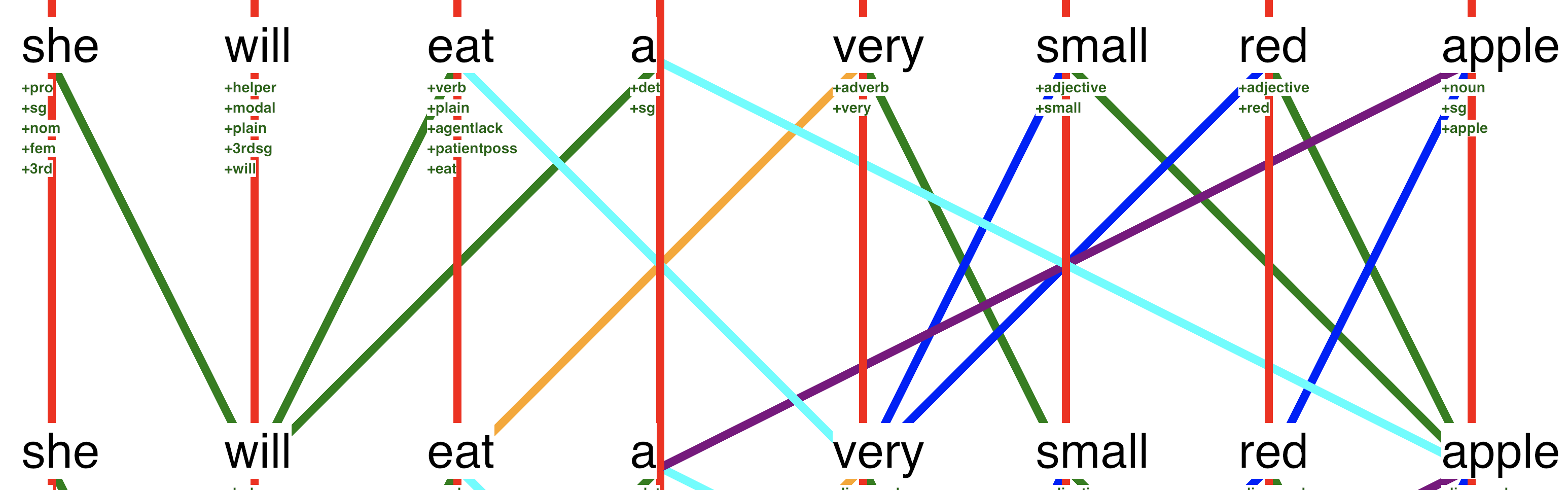
Here we demonstrate the use of the positional embedding in a self-attention layer by fixing the example from Section 4.4 to associate the correct noun with the correct adjective.
In this section, we show a Transformer programmed to make grammaticality judgments in English. This example is still in the process of being translated from one description language to another, and should not be expected to work. The full network that worked on a decent number of examples is shown as a comment in the code below.
In this section, we show a Transformer programmed to translate English to French. This network is solving a toy version of the problem (it can handle 300 or so sentences); the author has very little knowledge of French, unfortunately, which makes writing the decoder difficult.
Some text with links describing who reviewed the article.